秀丸エディタ・HmCustomStringEncoderの設定パラメータ解説
概要
ここでは、HmCustomStringEncoder
の主な設定パラメータの解説となります。
といっても、3種類しかありません。
#ToEncodeCodePage
-
意味合い
指定のエンコードに「これから変換すると何か問題が発生しますか?」
といった程度の意味合いとなります。 -
数値対象範囲
ここに記載されているコードページのすべてに対応しているものと思いますが、
こちらは(一部のコードページしか記載されていませんが)日本語なので、分かりやすく、参考になることでしょう。
すべてを確認したわけではないので、OSがVista等、古い場合は、
対象の言語圏のOSでないと指定ができないコードページがあるかもしれません。
-
デフォルト値
932。sjisです。
#NormalizeForm
-
意味合い
「文字列を正規化する度合い」、あるいは「範囲」といった方がよいかもしれません
Unicodeには「サロゲートペア」や「結合文字」があります。
焦点となるのは、この結合文字が中心となります。 -
結合可能な文字を、結合済み文字に整理する
例えば、「が」という文字は、
- 「が」に直接対応する「1コード」でも表現できますし、
- 「か+濁点」の2つのデータで合わせて1文字 といった形で表現しても扱うことができます。
#NormalizeFormに1以上を設定することで、
この「2つ以上のデータで合わせて1文字」を表現しているものは、
事前に「1つのデータ文字」として結合済みのものにしてから処理しますよ、ということになります。
上で言えば、先に「が」という「結合済みの文字」にしてから文字コード変換の調査を行います。 -
数値対象範囲
-
0
何もしない
結合文字をあぶりだしたい場合には、このオプションがよいかもしれません。 -
1
デフォルトです。
結合文字など、多数データで構成される文字に対して、NFCタイプのUnicode正規化を行います。
(詳細参照: Unicode正規化とは)元々1文字で表現されていたデータに対しては、Normalizeを行わないことで、NFCによる漢字変形の弊害を最小限に抑えます。
-
2
元々1文字のものも含めて、すべてをNFCタイプのUnicode正規化を行った後に、処理し結果を出します。
これによって一部の旧字体(やそのような雰囲気を持つ漢字)が、新字体(や日常的に利用する漢字の形)へと変形してしまう場合があります。
-
-
デフォルト値
1となります。
PushFallBackPairs
これについては、すでに利用法のページで体験した通りです。
デフォルトで記載してある「ペアの例」は、
特に意味があるようなものではありませんので、
削除したのち、ご自身の利用法に沿うものへと書き換えましょう。
「結合文字」を「結合済み文字」にしたいだけの場合
#ToEncodeCodePageを、「65001(=utf8)」や「1200(=utf16le)」などとし、
#NormalizeFormは「1」とします。
そうすれば、「結果のタブ」には可能な限り、結合済みの文字へと正規化された文字列が出力されます。
注意点
-
そのまま該当のエンコードで保存できる、と言えるものは、あくまで「結果」のタブ方
該当の文字コードで保存できる、と言えるのは、あくまでも「結果」の方のデータです。
下記で言えば、「HmCustomStringEncoder → [932]の結果」タブとして出た内容は、
SJISでエラー無く保存が可能なことでしょう。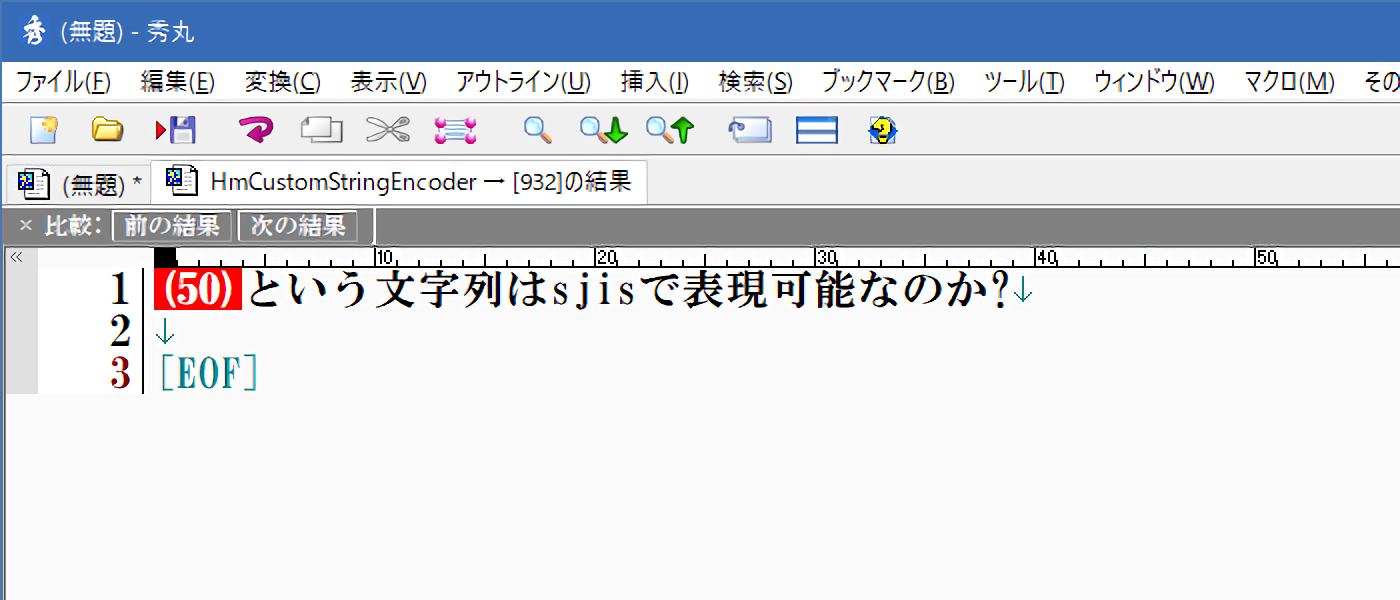
例え、「赤色が1カ所も出なかったしても」、
該当文字コードで保存が可能と言えるのは、あくまで「結果のタブ」に出ているものです。例えば、先述の「2つのデータで構成された『が』」は結合前の状態では、
秀丸でsjisとしては保存できないかもしれませんが、
「結果タブ」に出ている方は、結合した状態なので、保存が可能です。